The Charles Brockden Brown Electronic Archive: Mapping Archival Access and Metadata
By
Mark L. Kamrath, Philip Barnard, Rudy McDaniel, William Dorner, Kevin Jardaneh, Patricia Carlton, Josejuan Rodriguez
April 2014
In niches and pedestals, around the hall, stood the statues or busts of men, who, in every age, have been rulers and demi-gods in the realms of imagination, and kindred regions. The grand old countenance of Homer; the shrunken and decrepit form but vivid face of Æsop; the dark presence of Dante; the wild Aristo; Rabelais’s smile of deep-wrought mirth; the profound, pathetic humour of Cervantes; the all-glorious Shakespeare; Spenser, meet guest for an allegoric structure; the severe divinity of Milton; and Bunyan, moulded of homeliest clay, but instinct with celestial fire—were those that chiefly attracted my eye. Fielding, Richardson, and Scott, occupied conspicuous pedestals. In an obscure and shadowy niche was deposited the bust of our countryman, the author of Arthur Mervyn. — Nathaniel Hawthorne, “The Hall of Fantasy” (1842), allegorizing Brown’s standing as an American author among the world’s literary greats.1
¶ 2Leave a comment on paragraph 2 0
The Charles Brockden Brown Electronic Archive aims to collect the many writings of early American author Charles Brockden Brown and to integrate TEI-encoded primary and secondary materials into a searchable format that is interoperable with NINES (Networked Infrastructure for Nineteenth-Century Electronic Scholarship), an aggregator research tool.2 In exploring both the utopian view of archive technologies as an enabling framework to better understand humanistic data sets, and the practical challenges of such praxis in regards to a specific project within the digital humanities, this essay provides a behind-the scenes look at the types of archival, editorial, and technical issues—and decisions—involved in building a digital archive for a range of users. We also examine how the technological potentials of an electronic digital archive provide and encourage specific strategies and methods for structuring, parsing, searching, and organizing electronic literary texts. Such affordances provide opportunities for editors, scholars, and the general public to learn more about early American literature, culture, and textuality. Our project is also an exploration of the tension between French historian Natalis de Wailly’s concept of “respect des fonds” (maintaining “as one unit” all materials from one agency or department rather than arranging them according to library subject classification or another superimposed system), and more recent suggestions that understanding culture through technology (and databases, specifically) is an important and central goal of the digital humanities.3 The latter, as Jean Burgess and Axel Bruns have noted, provoke “new epistemological and methodological challenges” and questions.4
¶ 4Leave a comment on paragraph 4 0
Born to Quaker parents, Charles Brockden Brown (1771-1810) is the most significant novelist of the U.S. early national period. The seven novels he published in different formats between 1798 and 1801 contributed to the Gothic and epistolary traditions and are regarded today—as they were by Hawthorne, Poe, the Shelleys, and others—as major contributions to the literature of the Romantic era and the history of the novel.
¶ 5Leave a comment on paragraph 5 0
Brown was by no means exclusively a novelist, however. From the late 1790s to his death in 1810, he was also a prolific essayist, literary artist, and historian in a variety of genres. A polymath in the mode of Jefferson, Brown was a keen political and social thinker whose writings address a wide range of topics, from cultural and political history to sociology, the arts, and the physical sciences. To his peers, Brown was an internationally celebrated writer who was a primary contributor to three important magazines, produced influential political pamphlets, and wrote an important contemporary history of Atlantic geopolitics during the first decade of the nineteenth century.
¶ 6Leave a comment on paragraph 6 0
Brown’s contemporary admirers in the United States included figures such as Benjamin Rush (a signer of the Declaration of Independence, and the period’s preeminent American medical authority), William Dunlap (close friend and a founder of American theater), and Elihu Hubbard Smith (physician, close friend, and founder of the first American medical journal). In the next generation of U.S. writers, John Neal, Nathaniel Hawthorne, Edgar Allan Poe, George Lippard, Henry Dana, James Fenimore Cooper, Margaret Fuller, and John Greenleaf Whittier concurred in identifying Brown as a key predecessor and major figure in the development of antebellum literary culture. Cooper observed in his Notions of the Americans (1828) that “This author … enjoys a high reputation among his countrymen.” Hawthorne, in “P’s Correspondence,” a sketch in Moses from an Old Manse, wrote that “no American writer enjoys a more classic reputation on this side of the water.” And Poe, acknowledging his debt to Brown, remarked in his “Marginalia” (1844) that Hawthorne and Brown are “each a genus.”5 In an 1846 essay celebrating a new edition of Brown’s novels, Margaret Fuller identified him as one of “the dark masters” of Romantic-era fiction and judged that he was “far in advance of our other novelists.”6
¶ 7Leave a comment on paragraph 7 0
New scholarship in the last several decades has clarified the significance and scope of Brown’s large but hitherto lesser-known body of non-novelistic work—political pamphlets, periodical essays, reviews, stories, and poems. These writings, still widely scattered in archives and different proprietary databases, transform the consensus reading of Brown in dramatic ways, revealing a writer whose interests and intellectual achievements extend far beyond the scope of the novels and thereby change our understanding of the novels themselves. They also constitute a major body of cultural, social, and political commentary that increasingly interests not only literature specialists, but also historians and other interdisciplinary scholars working on the intellectual culture of the late Enlightenment and Revolutionary-era United States and Atlantic world.
¶ 8Leave a comment on paragraph 8 0
As the upsurge in Brown scholarship since 1980 has demonstrated, Brown’s novels and related writings explore fundamental questions about literary and political representation, nationalism and imperialism, U.S. expansionism and slavery, ethno-racial and sex-gender categories, and revolutionary-era transformations of print culture and the public sphere.7 Indeed, as Shirley Samuels of Cornell University observes in A Companion to American Fiction 1780-65, a high-level survey of the field, Brown’s work is currently understood as one of the major “compass points around which the study of American literature to 1865 can be oriented.”8
¶ 10Leave a comment on paragraph 10 0
In his seminal essay on digital archiving and planning, Daniel Pitti remarks that “designing complex, sustainable digital humanities projects and publications requires familiarity with both the research subject and available technologies,” and that the “design process is iterative,” with “each iteration” leading to “a coherent, integrated system.”9 Further, he notes, while “collaboration will enable greater productivity. . . . The most fundamental challenge of collaboration is balancing individual interests and shared objectives.”10 In this respect, the Brown project has grappled with bibliographical, textual, editorial, and technical issues since the 1960s, when Brown’s writings began receiving serious scholarly attention.
¶ 11Leave a comment on paragraph 11 0
Building on nearly fifty years of bibliographical and literary study, the Charles Brockden Brown Electronic Archive is integrating an immense collection of primary and secondary materials in order to make all of Brown’s novels, periodical writings, poems, and manuscript letters accessible electronically from a single location. As Ed Folsom, Lev Manovich, Jerome McGann, and others have pointed out over the last decade, however, “databases” have become a “genre” unto themselves insofar as they present text, images, and other data for scholarly use and are increasingly becoming the preferred mode of access for reading and archival research.11 Furthermore, as Stephen Ramsay has argued, the practical underpinnings of databases and their functionality suggest exciting research problems and areas of intellectual possibility worth engaging.12 For example, the authors of the Brown archive have worked to identify not only the relationship between various documents and periods, but also the appropriate user interface and units of metadata with which to represent disparate genres and make them searchable. The team has experimented with various ways of presenting those data sets and relationships to visitors of the archive.
¶ 12Leave a comment on paragraph 12 0
In what follows, we identify key moments or issues in the development of the archive that needed careful planning, discussion, consultation, collaboration, and resolution in order to reproduce manuscript and print texts in an electronic format that both scholars and the general public will find useful. Specifically, we outline decisions made in regard to bibliographical control, platform (XTF) selection, and interface design; textual transcription and OCR quality; quality of image reproduction; parameters for metadata presentation (TEI P5); protocols for proofreading; use of Library of Congress subject headings; integration with NINES; and procedures for server backup and the long-term preservation of data. We also examine the processes by which collaboration and practical experience guided project decisions and development, and the ways producing and using an archive both resemble and are distinct from the production of scholarly books and editions.
¶ 14Leave a comment on paragraph 14 0
As our project aims to accommodate a range of users and research styles—from students and advanced scholars, to the general American public, to more global users from other countries—we believe it is important to provide access to primary and secondary bibliographical content through traditional scrolling methods, enhanced interface and search capability, and an aggregation tool like NINES.
¶ 16Leave a comment on paragraph 16 0
In certain respects, the core of our project is a comprehensive primary bibliography of Brown’s writings, the result of decades of cumulative work by a number of U.S. and European scholars on Brown’s print output and the existing body of his manuscripts, which are located in archives across the United States. The result of this ongoing work is a master document titled “A Comprehensive Primary Bibliography of the Writings of Charles Brockden Brown, 1783–1822.” The bibliography lists the initial publications or manuscripts of all Brown’s known writings, and revises and updates earlier attempts at bibliographies, notably those of Charles E. Bennett (1974, 1976) and Alfred Weber (1961, 1987, 1992, 2003). The bibliography provides a listing of Brown’s writings that will be as complete as possible, within the limits imposed by the question of attributing anonymous periodical texts.13 In the spring of 2014, this listing included 984 texts or items in Brown’s extant corpus, subdivided into 7 novels, 179 letters (110 in manuscript, 69 from print sources), 43 other manuscript items ranging from notes and short poems to lengthy fictional narratives and a portfolio of architectural drawings, and 755 print publications, mostly periodical pieces in a wide variety of genres.
¶ 17Leave a comment on paragraph 17 0
In terms of sheer quantity, the largest single group of items in the extant Brown corpus is periodical publications. Given the anonymity of periodical publishing in the eighteenth and early-nineteenth centuries, however, it is often impossible to establish Brown’s authorship of periodical texts with complete certainty. His authorship of particular pieces may be obvious or historically attested in contemporary diaries, memoirs, or letters. The essay series “The Man at Home” (1798), for example, is identified as Brown’s work in the diary of a close friend, Elihu Hubbard Smith, and discussed in Brown’s own letters to friends. But Brown edited three magazines and produced many short pieces on a wide variety of topics, all of which appeared anonymously, which makes attribution for a large number of texts a substantial concern in establishing the corpus of his writings. Previous generations of scholars combed historical records for information documenting periodical authorship, and scholars have attempted to make attribution claims based on stylistic traits, although this latter method produced many claims that proved inaccurate.
¶ 18Leave a comment on paragraph 18 0
Fortunately for the present generation, the advent of digital reproduction has provided new and surprisingly powerful informational tools with which to explore the question of attribution in publications of this period. By searching strings of words from anonymous periodical articles in databases with texts from this period (currently even the Google Books database includes large numbers of eighteenth- and nineteenth-century periodicals), it is possible to learn with certainty, for example, that a text in one of Brown’s magazines is in fact partly or entirely reprinted from another periodical, thus either definitively eliminating it from Brown’s corpus or finding that it is in fact a “hybrid” text in which Brown has mixed his own prose with that from previously published articles. Likewise, these digital tools make it possible to identify the precise sources of Brown’s reprintings, which are almost always drawn from the leading British magazines of the period.
¶ 19Leave a comment on paragraph 19 0
This method of digital searching and checking produces interesting new knowledge for Brown scholarship, and it has already improved our understanding of Brown’s corpus in dramatic ways. Using digital archives in this manner, the project has eliminated over 450 items attributed to Brown in the pre-computer era and in early generations of the bibliography. This substantial change in the size and shape of the corpus provides a host of new insights into Brown’s career and editorial practices, and the resulting rigorous process of elimination provides a much higher degree of confidence in attributions. Not only do we now have a much clearer idea of the particular sources of Brown’s reprintings, we also gain greater clarity about the particular magazines and writers that Brown favored in this regard. For example, numerous periodical pieces attributed to Brown by earlier generations of scholars have turned out to be by Isaac D’Israeli (1766-1848, father of Benjamin D’Israeli), an essayist who flourished in London during the same period as Brown. Further, this work has made it clear that Brown’s second periodical, the Philadelphia Literary Magazine and American Register (1803-07), was substantially filled with such reprinted material. Future generations of scholars will be able to explore the patterns and implications of Brown’s selections, along with his writing style and syntactical choices, for example, in a way that was previously impossible.
¶ 20Leave a comment on paragraph 20 0
Earlier iterations of the Brown bibliography developed a system of coding to designate the degree of certainty for the attribution of each publication: “A” indicated that Brown’s authorship was known with certainty, while “B” indicated that Brown’s authorship was probable but not certain. As noted above, the project’s digital tools have allowed us to eliminate many items previously misattributed to Brown and thereby to strengthen the legitimacy of the “B” attributions that survive archival checks. Additionally, the power of these digital checks has led us to create a new, third category of attribution, using “H” to indicate hybrid texts in which Brown mixed his own prose with reprinted prose of other writers. In this instance as well, new digital tools have created an entirely new insight and body of knowledge concerning Brown’s writing and editorial practices. Given the large number of texts in question, and because existing digital archives, from Google Books to specialized scholarly databases, are constantly being augmented and improved, the power and reach of our digital tools increases every year and the bibliography can be improved and made more accurate over time. In this respect, the archive is organic and constantly being updated both by its editors and its users.
¶ 22Leave a comment on paragraph 22 0
The project’s secondary bibliography consists of scholarship (books, book chapters, journal articles, etc.) about Brown’s writings as well as the earliest reviews of his works. The current MLA International Bibliography extends back only to 1926, and existing bibliographies are dated and limited in scope; the project’s secondary bibliography, with its current public access, goes back to 1796 and can be browsed and scrolled. To enhance access, we have converted an ASCII text file of the entire bibliography to TEI P5 format and plan to integrate it into the XTF interface for multi-faceted searching using standard delimiting terms. For instance, one may search for “fiction NOT dissertation.”
¶ 23Leave a comment on paragraph 23 0
For this bibliography, we are locating any materials that relate or pertain to Charles Brockden Brown. This may be a dissertation, an article, or even a passing mention of Brown in a book. We are primarily using the Inter-Library Loan (ILL) system to retrieve these documents, as well as search engines for some of the materials that are more difficult to locate. Materials relating to Brown are spread through a vast span of time, with some dating back to the early-nineteenth century. As a result, these materials are extremely hard to find; a number are housed in special collections in various colleges around the United States.
¶ 24Leave a comment on paragraph 24 0
We are converting the materials found thus far to electronic form through scanning, except for those received electronically through ILL. After being converted, they are held in a database titled the “Charles Brockden Brown Project,” a file folder on a College of Arts and Humanities shared drive. They are cross referenced through two lists: the “secondary bibliography” list, a document containing all known secondary materials that lack MLA subject terms; and the aptly named “List with bib terms,” which lists all known documents that do have MLA subject terms. The process is ongoing, with new materials arriving daily.
¶ 25Leave a comment on paragraph 25 0
This process is laborious because many of these texts, printed or written over two hundred years ago, have ambiguous and difficult-to-read language. Any inconsistency is documented and addressed directly within the XML code to ensure complete fidelity to the original. The intent is to ensure the greatest possible level of accuracy across the electronic renditions—more than might be achieved with routine OCR. Although only structural elements of the text are initially tagged in the markup, we lay the groundwork for future expandability where possible.
¶ 26Leave a comment on paragraph 26 0
To date, we have identified, scanned, and filed (both electronically and in hardcopy) 1,150 journal essays, book chapter essays, and book abstracts, from a total of nearly 1,300 in our bibliography or archive. This process is 95 percent complete.
¶ 27Leave a comment on paragraph 27 0
By fall 2014, we plan to integrate Library of Congress (LC) subject headings into bibliography metadata for more robust searching. This will involveaugmenting the metadata with an LC subject-heading field and creating a thesaurus of authorized subject headings and sub-divisions. The Charles Brockden Brown subject-heading thesaurus will derive its headings and sub-divisions from the Library of Congress Authorities and will also include unauthorized or less restrictive “folksonomic” names and phrases for cross-referencing and redirecting to the authorized versions. For example, the abbreviation “CBB” and the phrase “Charles Brockden Brown” are both unauthorized but fairly common usages that would be redirected to documents containing the authorized subject heading of Brown, Charles Brockden, 1771-1810. Additionally, users will be able to consult the thesaurus to adjust their search terms to match the LC subject headings and sub-divisions, or perusing the index of subjects. The LC subject headings and their sub-divisions include genre, place, topic, or person, and will be fully integrated into the database, providing consistency and wide-ranging accessibility.
¶ 28Leave a comment on paragraph 28 0
The well-established schemas of LC classification and subject headings reduce confusion and afford precision, and they can be extended through proper nouns given as authorized subject headings and subdividing headings by topic, genre, chronology, or geography. However, as Thomas Vander Wal and the emerging field of “folksonomy” have revealed, traditional, highly structured classification systems or taxonomies are being influenced by less restrictive “collaborative tagging,” and thus play a role in our subject-heading classification and assignment.14 Assigning subject headings, of course, requires expert knowledge of the content; the archiving team must also understand and agree to the expected uses and terminology common to its patrons. To that end, the university’s librarians and editorial team are collaboratively discussing and anticipating future uses and trends in scholarly materials and artifacts associated with the archive.
¶ 30Leave a comment on paragraph 30 0
Matthew Kirschenbaum, Associate Director of the Maryland Institute for Technology in the Humanities (MITH), observes, “The idea of interface, and related concepts such as design and usability, are some of the most vexed in contemporary computing.”15 Yet well-designed platforms reward certain patterns of behavior and general tendencies exhibited by regular Internet users, providing the best possible user experience. The goal of this project is to provide the most accessible, most faithful, and comprehensive electronic rendition of all of Charles Brockden Brown’s writings via a single online resource, in such a way that we might later build in expanded scholarly research functionality. For instance, by coding and proofing all of Brown’s text in XML, we might add markup to associate different texts or isolate specific textual features, topics, historical events, etc.
¶ 31Leave a comment on paragraph 31 0
In order to facilitate this endeavor, it was important to select a highly customizable open-source platform and interface that would support a massive and varied repository of work, making publicly available and free of charge Brown’s often very obscure periodical and personal correspondence along with his novels. We also ensured that individual texts could be categorized, indexed, and retrieved via simple or advanced Boolean queries based on type, accession number, certainty of authorship, date of publication, and other specifiable metadata elements. After lengthy discussion with Daniel Pitti at the University of Virginia’s Institute for Advanced Technology in the Humanities (IATH), we selected the open-source eXtensible Text Framework (XTF) platform, developed by the California Digital Library, which employs Java and XSLT 2.0 code to index, query, and display digital objects online. Among its chief advantages—in addition to its wide use and support—are its flexibility and customizability, making it a simple matter to expand the TEI vocabulary we use for our documents. Moreover, it is possible to drastically change the display output of our documents without making any changes to the source TEI files.
¶ 32Leave a comment on paragraph 32 0
We also benefit from XTF’s customizable, user-friendly interface in a standard tabbed and text field layout. Users can select a simple keyword search, use advanced options, or browse the entire database with an array of refining hyperlinks, modified to provide the most useful search parameters. XTF also allows users to display automatically generated “similar items” to individual works browsed. The interface design’s universality allows first-time users to quickly navigate the various search options and localize their queries as necessary.
¶ 33Leave a comment on paragraph 33 0
In 2014, we plan to update the archive’s search interface, improving the site’s graphics and expanding index search options, integrating Boolean search using “OR,” “AND,” and “NOT” for both bibliographies into the site. Once the secondary bibliography has been integrated into the archive, researchers will be able to cross-reference primary and secondary works, attaining a level of intertextual scholarship and precision presently only available through a handful of sites, among them the Walt Whitman Archive.
¶ 36Leave a comment on paragraph 36 0
In December 2006, the Brown project contracted with Aptara to keyboard and encode in XML nearly 1,000 texts believed to be Brown’s that we have acquired to date. Aptara’s accuracy guarantee is a minimum of 99.95 percent (one error every 2,000 characters); the actual rate approached 99.99 percent (or one error every 10,000 characters). We determined that our DTD would be TEI Lite (P4).
¶ 37Leave a comment on paragraph 37 0
Our documentary texts replicate facsimile or JPEG manuscript images as accurately and closely as possible. Initial transcriptions are based upon print originals (letters) or high resolution TIFF, JPEG, or PDF images. Most of the print images were made available to us through ProQuest American Periodical Series Online. (See Figure 2.) The base-level encoding of Brown’s texts encompasses fundamental markup, including such requisite tags for header metadata and page-layout tags as <pb> for page breaks, <p> for paragraphs, and <lb> for line breaks. We display texts conservatively without correction of errors or regularization except for obvious date or pagination elements. We retain original line breaks and hyphenation in both holograph and print materials. In the case of Brown’s letters, we retain strikethroughs, underlining, and superscript insertions. We completed this stage of work in 2012.
¶ 38Leave a comment on paragraph 38 0Figure 2. This image illustrates the format and type face of Brown’s essay “The Difference between History and Romance,” which he published in The Monthly Magazine, and American Review in April 1800. Copied from images produced by ProQuest, LLC, Ann Arbor, MI 48106-1346. www.proquest.com.
During 2008–2009, we streamlined print and manuscript elements of the “Comprehensive Bibliography of the Writings of Charles Brockden Brown, 1783–1822,” and conducted additional header and body work, with the assistance of Syd Bauman of Brown University (he has since moved to Northeastern University), co-editor of TEI Guidelines for Electronic Text Encoding and Interchange. This work included converting texts from the TEI P4 to the P5 standard and revising our metadata, giving it more precise encoding for easier machine extraction. At the same time, we added encoding to accurately preserve end-line hyphenation in the transcription of each text, and we used Google Books to help identify and remove texts not written by Brown, thus reducing the database down to its present number.
¶ 40Leave a comment on paragraph 40 0
Our proofreading process is multi-tiered. Multiple readers compare original publication and manuscript texts side-by-side with their electronic facsimiles. A team of graduate students proofreads the first round and a team of undergraduate students reads the second, each documenting their findings. Project editors spot-check proofing for quality control. Our proofing method involves the following steps:
A Samsung Galaxy Tab 2 tablet, supported on an angled book stand, displays digital renditions from the archive side-by-side with original hardcopy printouts of PDFs or manuscript transcriptions, as appropriate.
Proofreaders compare the two texts line by line, looking for errors or inconsistencies in the digital display relative to the original text.
Errors or inconsistencies found in the first round are documented in pencil on the hardcopy printout of the original. Subsequent rounds employ different colored pens or pencils.
Figure 3. These two images (from the front and from the side) depict how a Samsung Galaxy 2 tablet and a hardcopy printout of a periodical text from the 1800s are used to proofread for transcription and coding accuracy.
¶ 42Leave a comment on paragraph 42 0
Once we have completely proofed the primary texts, a team of graduate students supervised by project faculty members will integrate the changes using TEI standards. Referencing the documented printouts, an XML-proficient graduate student will address both universal stylistic inconsistencies and text-specific coding errors on a case-by-case basis directly within the XML. Following a subsequent review to ensure all issues have been consistently and completely resolved, amended files will be re-indexed into the archive.
¶ 44Leave a comment on paragraph 44 0
Once TEI was selected as our encoding vehicle, we were faced with decisions about the type and amount of metadata to include in text files and to render through XTF.
¶ 45Leave a comment on paragraph 45 0
TEI guidelines provide an XML encoding system that describes the structure of a text, allowing users greater granularity once they have searched within Brown’s primary texts. TEI also allows metadata to be attached to the transcription of a text, facilitating faceted searching.
¶ 46Leave a comment on paragraph 46 0
One can manipulate and interface with XML via numerous software applications and systems. We integrated our TEI-encoded texts with a customized installation of XTF, which interprets and renders source XML documents for end users, allowing them to search a generated index using keyword queries; its search index includes both metadata and full content of each text. A typical TEI-XML document contains at least two elements below the root <TEI> element: the <teiHeader> and the <text> elements. The former contains such metadata as source description, provenance, and publication information about the TEI document, while the latter contains the entirety of the encoded text itself. XTF indexes all of this text and makes it searchable.
<text type=“magazine”> <body> <div> <pb n=“150”facs=“1807-02150-150.jpg”/> <head>CHARACTER OF DR. FRANKLIN.</head> <p>A just view of the character<lb/>
of Dr. Franklin has probably ne-<lb/>
ver been given by any of his<lb/>
countrymen. While living, the<lb/>
world was divided into passion-<lb/>
ate friends and rancorous ene-<lb/>
mies, and since his death a kind<lb/>
…
those studies which the learned<lb/>
have generally turned from in dis-<lb/>
dain. Respect is due to scholar-<lb/>
ship and science; but the value of<lb/>
these instruments is apt to be over-<lb/>
rated by their possessors; and it<lb/>
is a wholesome mortification, to<lb/>
show them that the work may be<lb/>
done without them.</p> </div> </body> </text>
¶ 54Leave a comment on paragraph 54 0
Within the <teiHeader>, the <titleStmt> contains information including the title of the TEI document as well as the various entities responsible for creating it, which could include an original author in addition to a coder or transcriber, indicated by <respStmt>. The <publicationStmt> contains metadata pertaining specifically to the XML document, and might include information about where the XML file is stored and its availability or copyright status. The <sourceDesc>, on the other hand, details the bibliographic information of the source document around which the XML was encoded. The <keywords> element indicates the genre of the text (“essay” in the above example), allowing the user to find it and other texts classified as an “essay” by entering that term as a search query in XTF. Other genre categories include “novel,” “poem,” “letter,” and more. Writings that can be classified in more than one genre (e.g., “letter” and “poem”) are identified as such in the metadata.
¶ 55Leave a comment on paragraph 55 0
The <body> element contains the entire textual content. Features we have marked up for representation include such structural elements as page, column, line breaks, paragraphs, and features specific to individual genres, such as stanzas, letter openers and closers, and footnotes. While column breaks in Brown’s double-column-printed works have been preserved and indicated within the markup, XTF currently displays the textual flow in a single column due to its default rendering of text in an HTML <table> element. We hope to provide more accurate representation in the future.
¶ 56Leave a comment on paragraph 56 0
Each entry in the primary bibliographic list of publications by Brown is represented in TEI by a <biblStruct> element, uniquely identified by the accession number. Each <biblStruct> in turn contains an <analytic> element, in which <author> and <title> information about an article, poem, essay, or other portion within a journal itself is found. Contained in <monogr> is the title of the publication, the editors of the publication if applicable, and the <imprint>, which houses the date and place of publication, as well as volume, issue, and pagination information. A typical entry in the secondary bibliography follows a pattern much like that of the primary bibliography in terms of publications within collections. For books published as individual items, the <analytic> element is excluded.
¶ 57Leave a comment on paragraph 57 0
Each full text by Brown will be contained within an XML file (named by accession number) that adheres to the general TEI P5 infrastructure, beginning with the <teiHeader> element laying out the bibliographic metadata about the TEI file itself in <fileDesc>, as well as information about the encoding of the text in <encodingDesc>. The file description statement lays out information about the file’s title, edition, and source text, including statements regarding distribution, access, and responsibility. Following the header, the <text> element contains the transcription of the text. Each file’s <text> contains at least fundamental page-layout tags, including <p> for paragraph, <lb/> for line break, and <pb> for page break.
¶ 59Leave a comment on paragraph 59 0
In regard to secondary bibliography metadata, we employ TEI markup to delineate standard information to assist in locating or identifying a single work, akin to information suggested by Modern Language Association (MLA) or American Psychological Association (APA) guidelines. This includes authors, titles, editors, editions, and publisher information, in addition to the custom TEI tag <cbb:subjects> to indicate subject matter keywords. Though the following example’s subjects will likely be revised, the <biblStruct> element is indicative of our coding method for secondary source metadata and subject terms:
<biblStruct> <analytic> <author>Burleigh, Erica</author> <title level=“a”>Incommensurate Equivalences: Genre, Representation, and Equity in Clara Howard and Jane Talbot</title> </analytic> <monogr> <title level=“j”>Early American Studies: An Interdisciplinary Journal</title> <imprint> <date>2011</date> <biblScope type=“vol”>9</biblScope> <biblScope type=“issue”>3</biblScope> <biblScope type=“pp”from=“748”to=“780”>748-780</biblScope> </imprint> <cbb:subjects>genre conventions; sentimental novel; marriage contract; promise; equality</cbb:subjects> </monogr> </biblStruct>
¶ 61Leave a comment on paragraph 61 0
Once all primary and secondary bibliographical data and archive contents, including Brown’s novels, have been coded, it will be submitted to NINES for review. Once the metadata has been approved, it will become searchable alongside other digital projects related to nineteenth-century cultural studies. Users of NINES can employ such tools as Collex to identify connections between diverse objects in peer-reviewed archives and projects. The NINES index is in SOLR and its user database is MySQL. NINES contributors identify such basic features of their digital objects as title, creator, publisher, date of composition, genre, and even a list of the component objects that make a greater whole.
¶ 62Leave a comment on paragraph 62 0
This enhancement pushes the field of early American literature forward digitally, in that our bibliographical and full-text metadata will become interoperable with the NINES digital aggregation tool.17 Collex is used to tag, remix, and re-purpose material within NINES. Use of RDF coding with Brown archive metadata will allow users to understand writing by and about Brown in a larger universe of historical inquiry and literary and cultural study. The ability to more efficiently juxtapose, for example, Brown’s ideas about poetic subjects with those of British women poets during the romantic era will be highly useful, as will, for instance, the ability to research his novels and political pamphlets alongside more contemporary texts. This will enrich the transatlantic and interdisciplinary study of Brown and further advance the use of digital media in early American literature studies.
¶ 64Leave a comment on paragraph 64 0
The issue of long-term storage and preservation of digitized assets and their recovery in the event of data corruption or other hardware failure remains a challenge. Other common problems include copyright issues (the ease with which content can be copied and distributed); technological obsolescence, making display of original content impossible; unstable network access, data corruption, and other instabilities; and the complexity of designing the appropriate interfaces and data views for an active interconnected system of XML files.
¶ 65Leave a comment on paragraph 65 0
Since the complexity of a proper backup for this archive exceeds normal support parameters for the College, our initial solution was to hire an outside consultant to help develop a Disaster Recovery Plan and implement an automated backup system that would run both incremental and full backups on a predetermined schedule. With this script developed and fully tested, a college systems administrator employee can handle our support needs.
¶ 66Leave a comment on paragraph 66 0
As an additional safeguard (and common funding requirement), the entire archive, including XML files, scanned images, and XSLT transformation and configuration files, should be backed up every six months on an external hard drive and stored off campus in case of a catastrophic emergency.18
¶ 67Leave a comment on paragraph 67 0
Our electronic bibliographies and searchable database are physically stored on a Dell PowerEdge 2900 server in the College of Arts and Humanities Technology unit. The server is configured with a RAID 5 hardware installation to ensure redundancy of the data and is housed in the College’s server room, which is equipped with power and data backup mechanisms. All backup sets are created with the built-in Linux utilities “tar” and “gzip.” Daily incremental backups are performed between full backup sets, and scheduling and set maintenance is performed automatically. In addition to storing weekly backup copies of XML files, the server is regularly maintained to ensure optimal performance. Original backups of XML files and TIFF images are also stored in the Center for Humanities and Digital Research. Because XML coding allows the project to adapt more easily than other formats, the project can adapt to emerging software interfaces and technologies in the future. With appropriate adjustments to the schema and transformation files, the data can adapt to other types of technological and scholarly applications.
¶ 68Leave a comment on paragraph 68 0
Authoring a DRP involves a rhetorical and process analysis on a system that deals with both computational and humanistic concerns. Who is the audience, what information do they need, how will they get it, and how does the computer facilitate that process? As David Giaretta notes, it is fundamental in digital asset preservation to ask three primary questions: preserve what, for how long, and for whom.19 Our team’s DRP covered what (all XML files, HTML/CSS files, transformation scripts, and image files of scanned documents), for how long (various durations depending on the type of backup and the current file size of existing backups), and for whom (our scholarly audiences and the general public as articulated in our original NEH proposal). Additionally, the system implemented a rotating schedule of both full and incremental backups, outlined below in Table 1. Multiple versions of full and incremental backups ensure recovery from most types of data failures.
¶ 70Leave a comment on paragraph 70 0
Our Linux script functions primarily by using the Python program fwbackups with a variety of special flags and conditional statements. The fwbackups script then uses the tar archiving program with gzip compression to reduce the size of the files and combine them into a single file that can be moved to other hard drives in case of primary drive failure. This script has since been handed off to our college’s systems administrator, who monitors and adjusts it as necessary.
¶ 71Leave a comment on paragraph 71 0
The current size of the full and incremental backups of the Brown archive is 112 GB for each backupset. The full backup is run automatically every Sunday and incremental backups run every evening. Total required backup space will soon reach half a terabyte, which may require us to reevaluate our procedure in order to keep data size manageable. Fortunately, hard drive costs have continued to trend downward and we are archiving mostly textual content rather than more size-intensive formats such as full-motion video.
¶ 73Leave a comment on paragraph 73 0
In a recent Inside Higher Ed blog post entitled “The Incredible Privilege of ‘Building,’” Lee Bessette raises the issue of “using versus building” in digital humanities work, asking “who” does it, and “why.” It is a topic—how “building and making” serves as a heuristic or means of discovering knowledge—that Jerome McGann, Stephan Ramsay, Lev Manovich, Mathew K. Gold, David Berry, and others have also engaged in their work.20
¶ 74Leave a comment on paragraph 74 0
We see from the way a database is used both in a material-specific way (deconstructing and representing fine divisions and relations in the text) and in a theoretical way (as a non-linear, decentralized, open-ended platform with multiple trajectories) that the database/archive potentially serves the digital humanist as a heuristic in the most enlightened sense of the word.
¶ 75Leave a comment on paragraph 75 0
As Rieder and Rohle note, “The use of computers as instruments, that is as heuristic tools that are part of a methodological chain, may not be the most visible part of the ‘digital revolution,’ but its institutional and epistemological repercussions for scholarship are already shaping up to be quite significant.”21
¶ 76Leave a comment on paragraph 76 0
This is the case with “building” the Brown archive relative to “respect des fonds” and the affordances of new media. It is an ongoing, dialectical process in regard to what to include in the archive relative to print publication and when to “publish” or make publically available; why we chose to represent texts the way we do; and how deep we have decided to code the texts at this time with current NEH funding. As much as it is a “product,” it is also a “work in progress.” In this respect, the long-term benefits of building this archive are three-fold:
Integrating TEI-encoded primary and secondary bibliographical materials into a single site interface dramatically enhances access to bibliographical resources. Both bibliographies are in an XML file format using TEI P5 (rather than a commercial content management system like Drupal),and are regularly updated—another unique reference innovation.
In addition to completing a high-end, searchable bibliography and interactive full-text database of all Brown’s works—including his letters and novels—the project’s integration of 8,083 JPEG images into 984 TEI-encoded texts carefully proofread for transcription errors, and its integration of both texts and images into XTF, will provide a powerful search tool allowing users access via genre, title, keyword, and other searches. This free, public access to all of Brown’s writings will generate new scholarship on his writing and on early American periodical literature and print culture generally. We anticipate that full-text archival access to Brown’s non-novelistic texts alone will generate a significant amount of new work, analogous to the remarkable wave of research on Brown that followed the NEH-funded Bicentennial edition of the novels.
A final major research advance pushing the field of early American literature itself forward digitally is the enhancement of bibliographical and full-text metadata so as to be interoperable with NINES. Use of RDF coding with Brown archive metadata will allow users to understand Brown’s writings, and writings about Brown, in a larger universe of historical inquiry and literary, philosophical, and cultural study.
¶ 78Leave a comment on paragraph 78 0
One distinguishing feature setting our project apart from other digital preservation and access projects is our effort to work collaboratively with commercial industry leaders in digital document collections and databases such as ProQuest and Readex Corporation. Our dialogue with commercial entities that are also developing innovative XML content tools demonstrates how collaboration across academic and commercial borders helps spark innovative thinking about usability and sustainability issues, and allows this project a unique vantage point from which to think about digital representation and access for students, teachers, scholars, and others. Moreover, as continual upgrades transform library information retrieval systems, and as major databases such as WorldCAT and the MLA International Bibliography move toward full-text access, we anticipate that archives like ours will be well positioned to contribute to this sort of migration and open-usage environment.
¶ 81Leave a comment on paragraph 81 0
We would like to thank Dana Wheeles, Brandon Walsh, and Linda Garrison for contributing their expertise in writing parts of this article. In addition to Daniel Pitti, Syd Bauman, and the Advisory Board of the Charles Brockden Brown Electronic Archive and Scholarly Edition, a debt of gratitude is also owed to Alfred Weber, Fritz Fleischmann, David Seaman, Mary Chapman, Terry Frederick, Bryce Jackson, Charles Bilodeau, Jorge Ramirez, Doug Maukonen, Lee Dotson, Selma Jaskowski, Michael Powell, Darryl Tucker, Matt Dunn, John Lazar, Jacob Skinner, and others for their role in planning, building, or managing some aspect of the Brown archive since its inception in 1998 (for a complete list of contributors, see “Participants” at the project website. More recently, Jordan Rigsby, Raichele Ricklefs, and Amy E. Giroux have contributed their assistance. We extend our gratitude as well to John Schlener, David Stabb, and Lalit Arora of Aptara.
¶ 82Leave a comment on paragraph 82 0
We also wish to thank Helen Agüera and the anonymous reviewers of the NEH Preservation and Access Program for their questions, comments, and insights concerning grant applications. The Brown archive has benefitted, especially during lean budget years, from the administrative support of Bruce Janz at the UCF Center for Humanities and Digital Research; Paul Lartonoix, Kristin Wetherbee, and Dean José Fernández of the UCF College of Arts and Humanities; and M. J. Soileau and Tom O’Neal of the UCF Office of Research and Commercialization. Lastly, we thank Fred Moody for his editorial expertise.
Nathaniel Hawthorne, Tales and Sketches (1843, repr.; New York: Library of America, 1982), 735. [↩]
Located at the University of Central Florida’s Center for Humanities and Digital Research, the project, is funded by a National Endowment for the Humanities (NEH) Preservation and Access Grant. Team members are currently proofreading nearly 900 TEI-encoded primary source materials, identifying over 1,200 secondary bibliography items for Library of Congress subject heading designations, and preparing metadata for integration with NINES. It is also exploring a similar affiliation with 18th Connect. [↩]
Laura Millar, Archives: Principles and Practices (New York: Neal-Schuman, 2010), 29-30. [↩]
Jean Burgess and Axel Bruns, “Twitter Archives and the Challenges of ‘Big Social Data’ for Media and Communication Research,” M/C Journal 15, no. 5 (Oct. 2012), http://www.journal.media-culture.org.au/index.php/mcjournal/article/view/561. [↩]
Philadelphia novelist and journalist George Lippard (1822–1854) also acknowledged a literary debt and included a lengthy dedication to Brown in his 1845 bestseller The Quaker City; or, The Monks of Monk Hall, and remarked in 1848 that Brown’s novels were read by “tens of thousands” in England, and that “men like Godwin or Bulwer, or even the crabbed Editor of a Scotch Review, hold this Philadelphia Novelist in high estimation, as a man of remarkable and original genius.” “The Heart-Broken,” in The Nineteenth Century: A Quarterly Miscellany 1.2 (January 1848), 22. James Fenimore Cooper, Notions of the Americans: Picked Up by a Travelling Bachelor (London: Henry Colbourn, 1828), 146; Edgar Allan Poe, “Marginalia,” in The United States Magazine and Democratic Review 15 (December 1844), 585. [↩]
Margaret Fuller, “Brown’s Novels,” in Margaret Fuller: Essays on American Life and Letters, ed. Joel Myerson (New Haven: College and University Press, 1978; essay first published in 1846), 375. [↩]
Philip Barnard, Mark L. Kamrath, and Stephen Shapiro, Revising Charles Brockden Brown: Culture, Politics, and Sexuality in the Early Republic (Knoxville: University of Tennessee Press, 2004), xiv-xvii. [↩]
Shirley Samuels, A Companion to American Fiction 1780-1865 (Malden, MA: Blackwell Publishing, 2004), 4. [↩]
Daniel Pitti, “Designing Sustainable Projects and Publications,” in A Companion to Digital Humanities, ed. Susan Schreibman, Ray Siemens, and John Unsworth (Malden, MA: Blackwell Publishing, 2004), 471, 473. [↩]
See Ed Folsom, “Database as Genre: The Epic Transformation of Archives,” Special Topic: Remapping Genre, PMLA 122, no. 5 (October 2007): 1571-79, along with “Responses to Ed Folsom’s ‘Database as Genre,’” 1580-1612. Other earlier influential studies on the subject of digital archive construction and use include Jerome J. McGann, Radiant Textuality: Literature after the World Wide Web (New York: Palgrave, 2001), and Richard J. Finnernan, The Literary Text in the Digital Age (Ann Arbor: University of Michigan Press, 1996). [↩]
Stephen Ramsay, “Databases,” in A Companion to Digital Humanities, ed. Susan Schreibman, Ray Siemens, and John Unsworth (Oxford: Blackwell, 2004), 177-197. [↩]
The bibliography’s initial version was the “Preliminary and Chronological Bibliography of … Uncollected Writings,” first developed in 2000 by Alfred Weber and Wolfgang Schäfer, and subsequently revised and emended by Fritz Fleischmann (2001–2003). Under U.S. law, copyright expires after seventy years. Brown died in 1810 and the last of his publications appeared in 1822. There are no copyright infringement issues since the bulk of the material in question, like other materials published before 1923, is now in the public domain. Further, there is no executor for Brown’s publications. [↩]
Thomas Vander Wal identifies two types of folksonomies—“broad” and “narrow”—and how they became popular on the Internet around 2004 as part of emerging social-media bookmarking and tagging. See his essays, “Explaining and Showing Broad and Narrow Folksonomies,” vanderwal.net (blog), February 21, 2005, http://www.vanderwal.net/random/entrysel.php?blog=1635, and “Folksonomy Coinage and Definition,” vandweral.net (blog), February 2, 2007, http://vanderwal.net/folksonomy.html. “Folksontology” examines how traditional hierarchical taxonomies and folksonomic classification can complement one another to create a single system of classification. [↩]
Matthew G. Kirschenbaum, “‘So the Colors Cover the Wires’: Interface, Aesthetics, and Usability,” in Schreibman, Siemens, and Unsworth, A Companion to Digital Humanities, 523. [↩]
This schema was adopted in consultation with Syd Bauman, Senior Programmer/Analyst, formerly of the Brown University Women’s Writers Project and currently an XML Programmer-Analyst for the Library Technology Services, among other projects, at Northeastern University. [↩]
NINES is a peer-review organization and an aggregator of digital resources that indexes metadata (RDF) contributed from numerous digital sites and archives. RDF is the metadata format that projects use to make their content interactive and available to users. Collex is the tool with which users can collect objects. A project cannot be a part of NINES without submitting RDF. NINES Peer Review Guidelines are located at http://www.nines.org/about/scholarship/peerReview.html. [↩]
At the moment, we feel that the backup system in place is as robust and comprehensive as current resources permit. However, were there a massive environmental catastrophe or burst water pipe, for example, the backup system would not be able to recover data since it still resides within the same physical room (although it is on another computer and another hard drive). A solution to this issue, which we are currently exploring, is to periodically store an additional copy of the backup data elsewhere on campus or with an offsite provider. [↩]
David Giaretta, Advanced Digital Preservation (London: Springer, 2011). [↩]
Lee Bessette, “The Incredible Privilege of “Building,’” Inside Higher Education, February 7, 2013, http://www.insidehighered.com/blogs/college-ready-writing/incredible-privilege-%E2%80%9Cbuilding%E2%80%9D. See, for instance, Ramsay, “Databases,” in Schreibman, Siemens, and Unsworth, A Companion to Digital Humanities; Lev Manovich, “Trending: The Promises and the Challenges of Big Social Data,” in Debates in the Digital Humanities, ed. Matthew K. Gold (Minneapolis: University of Minnesota Press, 2012), 460-75; David M. Berry, “Introduction: Understanding Digital Humanities,” in Understanding Digital Humanities, ed. David M. Berry (New York : Palgrave Macmillan, 2012), 1-20. [↩]
Bernhard Rieder and Theo Rohle, “Digital Methods: Five Challenges,” in Barry, Understanding Digital Humanities, 69. [↩]
Mark L. Kamrath
Associate Director, Center for Humanities and Digital Research; Professor of English – University of Central Florida General Editor, Charles Brockden Brown Electronic Archive and Scholarly Edition
Philip Barnard
Professor of English – University of Kansas
Rudy McDaniel
Assistant Dean of Research and Technology; Associate Professor of Digital Media; Director, Texts & Technology Doctoral Program – University of Central Florida
William Dorner
PhD Student in Texts & Technology – University of Central Florida
Kevin Jardaneh
PhD Student in Texts & Technology – University of Central Florida
Patricia Carlton
PhD Student in Texts & Technology – University of Central Florida
Josejuan Rodriguez
Undergraduate Student – University of Central Florida
The Charles Brockden Brown Electronic Archive: Mapping Archival Access and Metadata
By Mark L. Kamrath, Philip Barnard, Rudy McDaniel, William Dorner, Kevin Jardaneh, Patricia Carlton, Josejuan Rodriguez
April 2014
¶ 1 Leave a comment on paragraph 1 0
¶ 2 Leave a comment on paragraph 2 0 The Charles Brockden Brown Electronic Archive aims to collect the many writings of early American author Charles Brockden Brown and to integrate TEI-encoded primary and secondary materials into a searchable format that is interoperable with NINES (Networked Infrastructure for Nineteenth-Century Electronic Scholarship), an aggregator research tool.2 In exploring both the utopian view of archive technologies as an enabling framework to better understand humanistic data sets, and the practical challenges of such praxis in regards to a specific project within the digital humanities, this essay provides a behind-the scenes look at the types of archival, editorial, and technical issues—and decisions—involved in building a digital archive for a range of users. We also examine how the technological potentials of an electronic digital archive provide and encourage specific strategies and methods for structuring, parsing, searching, and organizing electronic literary texts. Such affordances provide opportunities for editors, scholars, and the general public to learn more about early American literature, culture, and textuality. Our project is also an exploration of the tension between French historian Natalis de Wailly’s concept of “respect des fonds” (maintaining “as one unit” all materials from one agency or department rather than arranging them according to library subject classification or another superimposed system), and more recent suggestions that understanding culture through technology (and databases, specifically) is an important and central goal of the digital humanities.3 The latter, as Jean Burgess and Axel Bruns have noted, provoke “new epistemological and methodological challenges” and questions.4
¶ 3 Leave a comment on paragraph 3 0 Biography and Cultural Significance
¶ 4 Leave a comment on paragraph 4 0 Born to Quaker parents, Charles Brockden Brown (1771-1810) is the most significant novelist of the U.S. early national period. The seven novels he published in different formats between 1798 and 1801 contributed to the Gothic and epistolary traditions and are regarded today—as they were by Hawthorne, Poe, the Shelleys, and others—as major contributions to the literature of the Romantic era and the history of the novel.
¶ 5 Leave a comment on paragraph 5 0 Brown was by no means exclusively a novelist, however. From the late 1790s to his death in 1810, he was also a prolific essayist, literary artist, and historian in a variety of genres. A polymath in the mode of Jefferson, Brown was a keen political and social thinker whose writings address a wide range of topics, from cultural and political history to sociology, the arts, and the physical sciences. To his peers, Brown was an internationally celebrated writer who was a primary contributor to three important magazines, produced influential political pamphlets, and wrote an important contemporary history of Atlantic geopolitics during the first decade of the nineteenth century.
¶ 6 Leave a comment on paragraph 6 0 Brown’s contemporary admirers in the United States included figures such as Benjamin Rush (a signer of the Declaration of Independence, and the period’s preeminent American medical authority), William Dunlap (close friend and a founder of American theater), and Elihu Hubbard Smith (physician, close friend, and founder of the first American medical journal). In the next generation of U.S. writers, John Neal, Nathaniel Hawthorne, Edgar Allan Poe, George Lippard, Henry Dana, James Fenimore Cooper, Margaret Fuller, and John Greenleaf Whittier concurred in identifying Brown as a key predecessor and major figure in the development of antebellum literary culture. Cooper observed in his Notions of the Americans (1828) that “This author … enjoys a high reputation among his countrymen.” Hawthorne, in “P’s Correspondence,” a sketch in Moses from an Old Manse, wrote that “no American writer enjoys a more classic reputation on this side of the water.” And Poe, acknowledging his debt to Brown, remarked in his “Marginalia” (1844) that Hawthorne and Brown are “each a genus.”5 In an 1846 essay celebrating a new edition of Brown’s novels, Margaret Fuller identified him as one of “the dark masters” of Romantic-era fiction and judged that he was “far in advance of our other novelists.”6
¶ 7 Leave a comment on paragraph 7 0 New scholarship in the last several decades has clarified the significance and scope of Brown’s large but hitherto lesser-known body of non-novelistic work—political pamphlets, periodical essays, reviews, stories, and poems. These writings, still widely scattered in archives and different proprietary databases, transform the consensus reading of Brown in dramatic ways, revealing a writer whose interests and intellectual achievements extend far beyond the scope of the novels and thereby change our understanding of the novels themselves. They also constitute a major body of cultural, social, and political commentary that increasingly interests not only literature specialists, but also historians and other interdisciplinary scholars working on the intellectual culture of the late Enlightenment and Revolutionary-era United States and Atlantic world.
¶ 8 Leave a comment on paragraph 8 0 As the upsurge in Brown scholarship since 1980 has demonstrated, Brown’s novels and related writings explore fundamental questions about literary and political representation, nationalism and imperialism, U.S. expansionism and slavery, ethno-racial and sex-gender categories, and revolutionary-era transformations of print culture and the public sphere.7 Indeed, as Shirley Samuels of Cornell University observes in A Companion to American Fiction 1780-65, a high-level survey of the field, Brown’s work is currently understood as one of the major “compass points around which the study of American literature to 1865 can be oriented.”8
¶ 9 Leave a comment on paragraph 9 0 Planning and Building a Digital Archive
¶ 10 Leave a comment on paragraph 10 0 In his seminal essay on digital archiving and planning, Daniel Pitti remarks that “designing complex, sustainable digital humanities projects and publications requires familiarity with both the research subject and available technologies,” and that the “design process is iterative,” with “each iteration” leading to “a coherent, integrated system.”9 Further, he notes, while “collaboration will enable greater productivity. . . . The most fundamental challenge of collaboration is balancing individual interests and shared objectives.”10 In this respect, the Brown project has grappled with bibliographical, textual, editorial, and technical issues since the 1960s, when Brown’s writings began receiving serious scholarly attention.
¶ 11 Leave a comment on paragraph 11 0 Building on nearly fifty years of bibliographical and literary study, the Charles Brockden Brown Electronic Archive is integrating an immense collection of primary and secondary materials in order to make all of Brown’s novels, periodical writings, poems, and manuscript letters accessible electronically from a single location. As Ed Folsom, Lev Manovich, Jerome McGann, and others have pointed out over the last decade, however, “databases” have become a “genre” unto themselves insofar as they present text, images, and other data for scholarly use and are increasingly becoming the preferred mode of access for reading and archival research.11 Furthermore, as Stephen Ramsay has argued, the practical underpinnings of databases and their functionality suggest exciting research problems and areas of intellectual possibility worth engaging.12 For example, the authors of the Brown archive have worked to identify not only the relationship between various documents and periods, but also the appropriate user interface and units of metadata with which to represent disparate genres and make them searchable. The team has experimented with various ways of presenting those data sets and relationships to visitors of the archive.
¶ 12 Leave a comment on paragraph 12 0 In what follows, we identify key moments or issues in the development of the archive that needed careful planning, discussion, consultation, collaboration, and resolution in order to reproduce manuscript and print texts in an electronic format that both scholars and the general public will find useful. Specifically, we outline decisions made in regard to bibliographical control, platform (XTF) selection, and interface design; textual transcription and OCR quality; quality of image reproduction; parameters for metadata presentation (TEI P5); protocols for proofreading; use of Library of Congress subject headings; integration with NINES; and procedures for server backup and the long-term preservation of data. We also examine the processes by which collaboration and practical experience guided project decisions and development, and the ways producing and using an archive both resemble and are distinct from the production of scholarly books and editions.
¶ 13 Leave a comment on paragraph 13 0 1. Bibliographical control
¶ 14 Leave a comment on paragraph 14 0 As our project aims to accommodate a range of users and research styles—from students and advanced scholars, to the general American public, to more global users from other countries—we believe it is important to provide access to primary and secondary bibliographical content through traditional scrolling methods, enhanced interface and search capability, and an aggregation tool like NINES.
¶ 15 Leave a comment on paragraph 15 0 Primary
¶ 16 Leave a comment on paragraph 16 0 In certain respects, the core of our project is a comprehensive primary bibliography of Brown’s writings, the result of decades of cumulative work by a number of U.S. and European scholars on Brown’s print output and the existing body of his manuscripts, which are located in archives across the United States. The result of this ongoing work is a master document titled “A Comprehensive Primary Bibliography of the Writings of Charles Brockden Brown, 1783–1822.” The bibliography lists the initial publications or manuscripts of all Brown’s known writings, and revises and updates earlier attempts at bibliographies, notably those of Charles E. Bennett (1974, 1976) and Alfred Weber (1961, 1987, 1992, 2003). The bibliography provides a listing of Brown’s writings that will be as complete as possible, within the limits imposed by the question of attributing anonymous periodical texts.13 In the spring of 2014, this listing included 984 texts or items in Brown’s extant corpus, subdivided into 7 novels, 179 letters (110 in manuscript, 69 from print sources), 43 other manuscript items ranging from notes and short poems to lengthy fictional narratives and a portfolio of architectural drawings, and 755 print publications, mostly periodical pieces in a wide variety of genres.
¶ 17 Leave a comment on paragraph 17 0 In terms of sheer quantity, the largest single group of items in the extant Brown corpus is periodical publications. Given the anonymity of periodical publishing in the eighteenth and early-nineteenth centuries, however, it is often impossible to establish Brown’s authorship of periodical texts with complete certainty. His authorship of particular pieces may be obvious or historically attested in contemporary diaries, memoirs, or letters. The essay series “The Man at Home” (1798), for example, is identified as Brown’s work in the diary of a close friend, Elihu Hubbard Smith, and discussed in Brown’s own letters to friends. But Brown edited three magazines and produced many short pieces on a wide variety of topics, all of which appeared anonymously, which makes attribution for a large number of texts a substantial concern in establishing the corpus of his writings. Previous generations of scholars combed historical records for information documenting periodical authorship, and scholars have attempted to make attribution claims based on stylistic traits, although this latter method produced many claims that proved inaccurate.
¶ 18 Leave a comment on paragraph 18 0 Fortunately for the present generation, the advent of digital reproduction has provided new and surprisingly powerful informational tools with which to explore the question of attribution in publications of this period. By searching strings of words from anonymous periodical articles in databases with texts from this period (currently even the Google Books database includes large numbers of eighteenth- and nineteenth-century periodicals), it is possible to learn with certainty, for example, that a text in one of Brown’s magazines is in fact partly or entirely reprinted from another periodical, thus either definitively eliminating it from Brown’s corpus or finding that it is in fact a “hybrid” text in which Brown has mixed his own prose with that from previously published articles. Likewise, these digital tools make it possible to identify the precise sources of Brown’s reprintings, which are almost always drawn from the leading British magazines of the period.
¶ 19 Leave a comment on paragraph 19 0 This method of digital searching and checking produces interesting new knowledge for Brown scholarship, and it has already improved our understanding of Brown’s corpus in dramatic ways. Using digital archives in this manner, the project has eliminated over 450 items attributed to Brown in the pre-computer era and in early generations of the bibliography. This substantial change in the size and shape of the corpus provides a host of new insights into Brown’s career and editorial practices, and the resulting rigorous process of elimination provides a much higher degree of confidence in attributions. Not only do we now have a much clearer idea of the particular sources of Brown’s reprintings, we also gain greater clarity about the particular magazines and writers that Brown favored in this regard. For example, numerous periodical pieces attributed to Brown by earlier generations of scholars have turned out to be by Isaac D’Israeli (1766-1848, father of Benjamin D’Israeli), an essayist who flourished in London during the same period as Brown. Further, this work has made it clear that Brown’s second periodical, the Philadelphia Literary Magazine and American Register (1803-07), was substantially filled with such reprinted material. Future generations of scholars will be able to explore the patterns and implications of Brown’s selections, along with his writing style and syntactical choices, for example, in a way that was previously impossible.
¶ 20 Leave a comment on paragraph 20 0 Earlier iterations of the Brown bibliography developed a system of coding to designate the degree of certainty for the attribution of each publication: “A” indicated that Brown’s authorship was known with certainty, while “B” indicated that Brown’s authorship was probable but not certain. As noted above, the project’s digital tools have allowed us to eliminate many items previously misattributed to Brown and thereby to strengthen the legitimacy of the “B” attributions that survive archival checks. Additionally, the power of these digital checks has led us to create a new, third category of attribution, using “H” to indicate hybrid texts in which Brown mixed his own prose with reprinted prose of other writers. In this instance as well, new digital tools have created an entirely new insight and body of knowledge concerning Brown’s writing and editorial practices. Given the large number of texts in question, and because existing digital archives, from Google Books to specialized scholarly databases, are constantly being augmented and improved, the power and reach of our digital tools increases every year and the bibliography can be improved and made more accurate over time. In this respect, the archive is organic and constantly being updated both by its editors and its users.
¶ 21 Leave a comment on paragraph 21 0 Secondary
¶ 22 Leave a comment on paragraph 22 0 The project’s secondary bibliography consists of scholarship (books, book chapters, journal articles, etc.) about Brown’s writings as well as the earliest reviews of his works. The current MLA International Bibliography extends back only to 1926, and existing bibliographies are dated and limited in scope; the project’s secondary bibliography, with its current public access, goes back to 1796 and can be browsed and scrolled. To enhance access, we have converted an ASCII text file of the entire bibliography to TEI P5 format and plan to integrate it into the XTF interface for multi-faceted searching using standard delimiting terms. For instance, one may search for “fiction NOT dissertation.”
¶ 23 Leave a comment on paragraph 23 0 For this bibliography, we are locating any materials that relate or pertain to Charles Brockden Brown. This may be a dissertation, an article, or even a passing mention of Brown in a book. We are primarily using the Inter-Library Loan (ILL) system to retrieve these documents, as well as search engines for some of the materials that are more difficult to locate. Materials relating to Brown are spread through a vast span of time, with some dating back to the early-nineteenth century. As a result, these materials are extremely hard to find; a number are housed in special collections in various colleges around the United States.
¶ 24 Leave a comment on paragraph 24 0 We are converting the materials found thus far to electronic form through scanning, except for those received electronically through ILL. After being converted, they are held in a database titled the “Charles Brockden Brown Project,” a file folder on a College of Arts and Humanities shared drive. They are cross referenced through two lists: the “secondary bibliography” list, a document containing all known secondary materials that lack MLA subject terms; and the aptly named “List with bib terms,” which lists all known documents that do have MLA subject terms. The process is ongoing, with new materials arriving daily.
¶ 25 Leave a comment on paragraph 25 0 This process is laborious because many of these texts, printed or written over two hundred years ago, have ambiguous and difficult-to-read language. Any inconsistency is documented and addressed directly within the XML code to ensure complete fidelity to the original. The intent is to ensure the greatest possible level of accuracy across the electronic renditions—more than might be achieved with routine OCR. Although only structural elements of the text are initially tagged in the markup, we lay the groundwork for future expandability where possible.
¶ 26 Leave a comment on paragraph 26 0 To date, we have identified, scanned, and filed (both electronically and in hardcopy) 1,150 journal essays, book chapter essays, and book abstracts, from a total of nearly 1,300 in our bibliography or archive. This process is 95 percent complete.
¶ 27 Leave a comment on paragraph 27 0 By fall 2014, we plan to integrate Library of Congress (LC) subject headings into bibliography metadata for more robust searching. This will involve augmenting the metadata with an LC subject-heading field and creating a thesaurus of authorized subject headings and sub-divisions. The Charles Brockden Brown subject-heading thesaurus will derive its headings and sub-divisions from the Library of Congress Authorities and will also include unauthorized or less restrictive “folksonomic” names and phrases for cross-referencing and redirecting to the authorized versions. For example, the abbreviation “CBB” and the phrase “Charles Brockden Brown” are both unauthorized but fairly common usages that would be redirected to documents containing the authorized subject heading of Brown, Charles Brockden, 1771-1810. Additionally, users will be able to consult the thesaurus to adjust their search terms to match the LC subject headings and sub-divisions, or perusing the index of subjects. The LC subject headings and their sub-divisions include genre, place, topic, or person, and will be fully integrated into the database, providing consistency and wide-ranging accessibility.
¶ 28 Leave a comment on paragraph 28 0 The well-established schemas of LC classification and subject headings reduce confusion and afford precision, and they can be extended through proper nouns given as authorized subject headings and subdividing headings by topic, genre, chronology, or geography. However, as Thomas Vander Wal and the emerging field of “folksonomy” have revealed, traditional, highly structured classification systems or taxonomies are being influenced by less restrictive “collaborative tagging,” and thus play a role in our subject-heading classification and assignment.14 Assigning subject headings, of course, requires expert knowledge of the content; the archiving team must also understand and agree to the expected uses and terminology common to its patrons. To that end, the university’s librarians and editorial team are collaboratively discussing and anticipating future uses and trends in scholarly materials and artifacts associated with the archive.
¶ 29 Leave a comment on paragraph 29 0 2. Platform selection and interface
¶ 30 Leave a comment on paragraph 30 0 Matthew Kirschenbaum, Associate Director of the Maryland Institute for Technology in the Humanities (MITH), observes, “The idea of interface, and related concepts such as design and usability, are some of the most vexed in contemporary computing.”15 Yet well-designed platforms reward certain patterns of behavior and general tendencies exhibited by regular Internet users, providing the best possible user experience. The goal of this project is to provide the most accessible, most faithful, and comprehensive electronic rendition of all of Charles Brockden Brown’s writings via a single online resource, in such a way that we might later build in expanded scholarly research functionality. For instance, by coding and proofing all of Brown’s text in XML, we might add markup to associate different texts or isolate specific textual features, topics, historical events, etc.
¶ 31 Leave a comment on paragraph 31 0 In order to facilitate this endeavor, it was important to select a highly customizable open-source platform and interface that would support a massive and varied repository of work, making publicly available and free of charge Brown’s often very obscure periodical and personal correspondence along with his novels. We also ensured that individual texts could be categorized, indexed, and retrieved via simple or advanced Boolean queries based on type, accession number, certainty of authorship, date of publication, and other specifiable metadata elements. After lengthy discussion with Daniel Pitti at the University of Virginia’s Institute for Advanced Technology in the Humanities (IATH), we selected the open-source eXtensible Text Framework (XTF) platform, developed by the California Digital Library, which employs Java and XSLT 2.0 code to index, query, and display digital objects online. Among its chief advantages—in addition to its wide use and support—are its flexibility and customizability, making it a simple matter to expand the TEI vocabulary we use for our documents. Moreover, it is possible to drastically change the display output of our documents without making any changes to the source TEI files.
¶ 32 Leave a comment on paragraph 32 0 We also benefit from XTF’s customizable, user-friendly interface in a standard tabbed and text field layout. Users can select a simple keyword search, use advanced options, or browse the entire database with an array of refining hyperlinks, modified to provide the most useful search parameters. XTF also allows users to display automatically generated “similar items” to individual works browsed. The interface design’s universality allows first-time users to quickly navigate the various search options and localize their queries as necessary.
¶ 33 Leave a comment on paragraph 33 0 In 2014, we plan to update the archive’s search interface, improving the site’s graphics and expanding index search options, integrating Boolean search using “OR,” “AND,” and “NOT” for both bibliographies into the site. Once the secondary bibliography has been integrated into the archive, researchers will be able to cross-reference primary and secondary works, attaining a level of intertextual scholarship and precision presently only available through a handful of sites, among them the Walt Whitman Archive.
¶ 34 Leave a comment on paragraph 34 0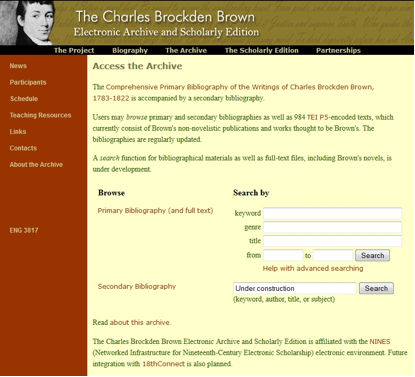 Figure 1. This screen shot illustrates the archive’s interface design.
Figure 1. This screen shot illustrates the archive’s interface design.
3. Textual reproduction, OCR, and accuracy
¶ 36 Leave a comment on paragraph 36 0 In December 2006, the Brown project contracted with Aptara to keyboard and encode in XML nearly 1,000 texts believed to be Brown’s that we have acquired to date. Aptara’s accuracy guarantee is a minimum of 99.95 percent (one error every 2,000 characters); the actual rate approached 99.99 percent (or one error every 10,000 characters). We determined that our DTD would be TEI Lite (P4).
¶ 37 Leave a comment on paragraph 37 0 Our documentary texts replicate facsimile or JPEG manuscript images as accurately and closely as possible. Initial transcriptions are based upon print originals (letters) or high resolution TIFF, JPEG, or PDF images. Most of the print images were made available to us through ProQuest American Periodical Series Online. (See Figure 2.) The base-level encoding of Brown’s texts encompasses fundamental markup, including such requisite tags for header metadata and page-layout tags as <pb> for page breaks, <p> for paragraphs, and <lb> for line breaks. We display texts conservatively without correction of errors or regularization except for obvious date or pagination elements. We retain original line breaks and hyphenation in both holograph and print materials. In the case of Brown’s letters, we retain strikethroughs, underlining, and superscript insertions. We completed this stage of work in 2012.
¶ 38 Leave a comment on paragraph 38 0 Figure 2. This image illustrates the format and type face of Brown’s essay “The Difference between History and Romance,” which he published in The Monthly Magazine, and American Review in April 1800.
Figure 2. This image illustrates the format and type face of Brown’s essay “The Difference between History and Romance,” which he published in The Monthly Magazine, and American Review in April 1800.
Copied from images produced by ProQuest, LLC, Ann Arbor, MI 48106-1346. www.proquest.com.
During 2008–2009, we streamlined print and manuscript elements of the “Comprehensive Bibliography of the Writings of Charles Brockden Brown, 1783–1822,” and conducted additional header and body work, with the assistance of Syd Bauman of Brown University (he has since moved to Northeastern University), co-editor of TEI Guidelines for Electronic Text Encoding and Interchange. This work included converting texts from the TEI P4 to the P5 standard and revising our metadata, giving it more precise encoding for easier machine extraction. At the same time, we added encoding to accurately preserve end-line hyphenation in the transcription of each text, and we used Google Books to help identify and remove texts not written by Brown, thus reducing the database down to its present number.
¶ 40 Leave a comment on paragraph 40 0 Our proofreading process is multi-tiered. Multiple readers compare original publication and manuscript texts side-by-side with their electronic facsimiles. A team of graduate students proofreads the first round and a team of undergraduate students reads the second, each documenting their findings. Project editors spot-check proofing for quality control. Our proofing method involves the following steps:
¶ 42 Leave a comment on paragraph 42 0 Once we have completely proofed the primary texts, a team of graduate students supervised by project faculty members will integrate the changes using TEI standards. Referencing the documented printouts, an XML-proficient graduate student will address both universal stylistic inconsistencies and text-specific coding errors on a case-by-case basis directly within the XML. Following a subsequent review to ensure all issues have been consistently and completely resolved, amended files will be re-indexed into the archive.
¶ 43 Leave a comment on paragraph 43 0 4. TEI coding standards and specifications
¶ 44 Leave a comment on paragraph 44 0 Once TEI was selected as our encoding vehicle, we were faced with decisions about the type and amount of metadata to include in text files and to render through XTF.
¶ 45 Leave a comment on paragraph 45 0 TEI guidelines provide an XML encoding system that describes the structure of a text, allowing users greater granularity once they have searched within Brown’s primary texts. TEI also allows metadata to be attached to the transcription of a text, facilitating faceted searching.
¶ 46 Leave a comment on paragraph 46 0 One can manipulate and interface with XML via numerous software applications and systems. We integrated our TEI-encoded texts with a customized installation of XTF, which interprets and renders source XML documents for end users, allowing them to search a generated index using keyword queries; its search index includes both metadata and full content of each text. A typical TEI-XML document contains at least two elements below the root <TEI> element: the <teiHeader> and the <text> elements. The former contains such metadata as source description, provenance, and publication information about the TEI document, while the latter contains the entirety of the encoded text itself. XTF indexes all of this text and makes it searchable.
¶ 47 Leave a comment on paragraph 47 0 We employ the following (header and body) schema for our files:16
¶ 48 Leave a comment on paragraph 48 0 A TEI <teiHeader> element:
<teiHeader>
<fileDesc>
<titleStmt>
<title type=“main”>Character of Dr. Franklin</title>
<title type=“version”>TEI Document</title>
<author cbb:cert=“hybrid”>Brown, Charles Brockden</author>
<respStmt>
<resp>transcription and initial TEI coding</resp>
<orgName>Aptara</orgName>
</respStmt>
<respStmt>
<resp>TEI encoding enhancement</resp>
<name>Mark L. Kamrath</name>
<name>Philip Barnard</name>
<name>William Dorner</name>
</respStmt>
</titleStmt>
<editionStmt>
<edition>TEI P5</edition>
</editionStmt>
<publicationStmt>
<publisher>The Charles Brockden Brown Electronic Archive and Scholarly Edition</publisher>
<address>
<postBox>P.O. 161346</postBox>
<orgName>University of Central Florida</orgName>
<settlement>Orlando</settlement>
<region>FL</region>
<postCode>32816</postCode>
</address>
<idno type=“accession”>1807-02150</idno>
<date when=“2009-01”/>
<availability status=“restricted”>
<p>Copyright 2009 The Charles Brockden Brown Electronic Archive and Scholarly Edition.</p>
</availability>
</publicationStmt>
<sourceDesc>
<biblStruct>
<analytic>
<author>Brown, Charles Brockden</author>
<title>Character of Dr. Franklin</title>
</analytic>
<monogr>
<title level=“j”>American Register</title>
<imprint>
<biblScope type=“vol”>I</biblScope>
<date when=“1807”/>
<biblScope type=“pp”>150-159</biblScope>
</imprint>
</monogr>
</biblStruct>
</sourceDesc>
</fileDesc>
<xi:include href=“./cbb_encodingDesc.xml”/>
<profileDesc>
<textClass>
<keywords scheme=“#CBB_keywords”><term>essay</term></keywords>
</textClass>
</profileDesc>
</teiHeader>
¶ 50 Leave a comment on paragraph 50 0 A TEI <text> element:
<text type=“magazine”>
<body>
<div>
<pb n=“150” facs=“1807-02150-150.jpg”/>
<head>CHARACTER OF DR. FRANKLIN.</head>
<p>A just view of the character<lb/>
of Dr. Franklin has probably ne-<lb/>
ver been given by any of his<lb/>
countrymen. While living, the<lb/>
world was divided into passion-<lb/>
ate friends and rancorous ene-<lb/>
mies, and since his death a kind<lb/>
…
those studies which the learned<lb/>
have generally turned from in dis-<lb/>
dain. Respect is due to scholar-<lb/>
ship and science; but the value of<lb/>
these instruments is apt to be over-<lb/>
rated by their possessors; and it<lb/>
is a wholesome mortification, to<lb/>
show them that the work may be<lb/>
done without them.</p>
</div>
</body>
</text>
¶ 54 Leave a comment on paragraph 54 0 Within the <teiHeader>, the <titleStmt> contains information including the title of the TEI document as well as the various entities responsible for creating it, which could include an original author in addition to a coder or transcriber, indicated by <respStmt>. The <publicationStmt> contains metadata pertaining specifically to the XML document, and might include information about where the XML file is stored and its availability or copyright status. The <sourceDesc>, on the other hand, details the bibliographic information of the source document around which the XML was encoded. The <keywords> element indicates the genre of the text (“essay” in the above example), allowing the user to find it and other texts classified as an “essay” by entering that term as a search query in XTF. Other genre categories include “novel,” “poem,” “letter,” and more. Writings that can be classified in more than one genre (e.g., “letter” and “poem”) are identified as such in the metadata.
¶ 55 Leave a comment on paragraph 55 0 The <body> element contains the entire textual content. Features we have marked up for representation include such structural elements as page, column, line breaks, paragraphs, and features specific to individual genres, such as stanzas, letter openers and closers, and footnotes. While column breaks in Brown’s double-column-printed works have been preserved and indicated within the markup, XTF currently displays the textual flow in a single column due to its default rendering of text in an HTML <table> element. We hope to provide more accurate representation in the future.
¶ 56 Leave a comment on paragraph 56 0 Each entry in the primary bibliographic list of publications by Brown is represented in TEI by a <biblStruct> element, uniquely identified by the accession number. Each <biblStruct> in turn contains an <analytic> element, in which <author> and <title> information about an article, poem, essay, or other portion within a journal itself is found. Contained in <monogr> is the title of the publication, the editors of the publication if applicable, and the <imprint>, which houses the date and place of publication, as well as volume, issue, and pagination information. A typical entry in the secondary bibliography follows a pattern much like that of the primary bibliography in terms of publications within collections. For books published as individual items, the <analytic> element is excluded.
¶ 57 Leave a comment on paragraph 57 0 Each full text by Brown will be contained within an XML file (named by accession number) that adheres to the general TEI P5 infrastructure, beginning with the <teiHeader> element laying out the bibliographic metadata about the TEI file itself in <fileDesc>, as well as information about the encoding of the text in <encodingDesc>. The file description statement lays out information about the file’s title, edition, and source text, including statements regarding distribution, access, and responsibility. Following the header, the <text> element contains the transcription of the text. Each file’s <text> contains at least fundamental page-layout tags, including <p> for paragraph, <lb/> for line break, and <pb> for page break.
¶ 58 Leave a comment on paragraph 58 0 5. Metadata enhancement and NINES
¶ 59 Leave a comment on paragraph 59 0 In regard to secondary bibliography metadata, we employ TEI markup to delineate standard information to assist in locating or identifying a single work, akin to information suggested by Modern Language Association (MLA) or American Psychological Association (APA) guidelines. This includes authors, titles, editors, editions, and publisher information, in addition to the custom TEI tag <cbb:subjects> to indicate subject matter keywords. Though the following example’s subjects will likely be revised, the <biblStruct> element is indicative of our coding method for secondary source metadata and subject terms:
<biblStruct>
<analytic>
<author>Burleigh, Erica</author>
<title level=“a”>Incommensurate Equivalences: Genre, Representation, and Equity in Clara Howard and Jane Talbot</title>
</analytic>
<monogr>
<title level=“j”>Early American Studies: An Interdisciplinary Journal</title>
<imprint>
<date>2011</date>
<biblScope type=“vol”>9</biblScope>
<biblScope type=“issue”>3</biblScope>
<biblScope type=“pp” from=“748” to=“780”>748-780</biblScope>
</imprint>
<cbb:subjects>genre conventions; sentimental novel; marriage contract; promise; equality</cbb:subjects>
</monogr>
</biblStruct>
¶ 61 Leave a comment on paragraph 61 0 Once all primary and secondary bibliographical data and archive contents, including Brown’s novels, have been coded, it will be submitted to NINES for review. Once the metadata has been approved, it will become searchable alongside other digital projects related to nineteenth-century cultural studies. Users of NINES can employ such tools as Collex to identify connections between diverse objects in peer-reviewed archives and projects. The NINES index is in SOLR and its user database is MySQL. NINES contributors identify such basic features of their digital objects as title, creator, publisher, date of composition, genre, and even a list of the component objects that make a greater whole.
¶ 62 Leave a comment on paragraph 62 0 This enhancement pushes the field of early American literature forward digitally, in that our bibliographical and full-text metadata will become interoperable with the NINES digital aggregation tool.17 Collex is used to tag, remix, and re-purpose material within NINES. Use of RDF coding with Brown archive metadata will allow users to understand writing by and about Brown in a larger universe of historical inquiry and literary and cultural study. The ability to more efficiently juxtapose, for example, Brown’s ideas about poetic subjects with those of British women poets during the romantic era will be highly useful, as will, for instance, the ability to research his novels and political pamphlets alongside more contemporary texts. This will enrich the transatlantic and interdisciplinary study of Brown and further advance the use of digital media in early American literature studies.
¶ 63 Leave a comment on paragraph 63 0 6. Server backup and preservation
¶ 64 Leave a comment on paragraph 64 0 The issue of long-term storage and preservation of digitized assets and their recovery in the event of data corruption or other hardware failure remains a challenge. Other common problems include copyright issues (the ease with which content can be copied and distributed); technological obsolescence, making display of original content impossible; unstable network access, data corruption, and other instabilities; and the complexity of designing the appropriate interfaces and data views for an active interconnected system of XML files.
¶ 65 Leave a comment on paragraph 65 0 Since the complexity of a proper backup for this archive exceeds normal support parameters for the College, our initial solution was to hire an outside consultant to help develop a Disaster Recovery Plan and implement an automated backup system that would run both incremental and full backups on a predetermined schedule. With this script developed and fully tested, a college systems administrator employee can handle our support needs.
¶ 66 Leave a comment on paragraph 66 0 As an additional safeguard (and common funding requirement), the entire archive, including XML files, scanned images, and XSLT transformation and configuration files, should be backed up every six months on an external hard drive and stored off campus in case of a catastrophic emergency.18
¶ 67 Leave a comment on paragraph 67 0 Our electronic bibliographies and searchable database are physically stored on a Dell PowerEdge 2900 server in the College of Arts and Humanities Technology unit. The server is configured with a RAID 5 hardware installation to ensure redundancy of the data and is housed in the College’s server room, which is equipped with power and data backup mechanisms. All backup sets are created with the built-in Linux utilities “tar” and “gzip.” Daily incremental backups are performed between full backup sets, and scheduling and set maintenance is performed automatically. In addition to storing weekly backup copies of XML files, the server is regularly maintained to ensure optimal performance. Original backups of XML files and TIFF images are also stored in the Center for Humanities and Digital Research. Because XML coding allows the project to adapt more easily than other formats, the project can adapt to emerging software interfaces and technologies in the future. With appropriate adjustments to the schema and transformation files, the data can adapt to other types of technological and scholarly applications.
¶ 68 Leave a comment on paragraph 68 0 Authoring a DRP involves a rhetorical and process analysis on a system that deals with both computational and humanistic concerns. Who is the audience, what information do they need, how will they get it, and how does the computer facilitate that process? As David Giaretta notes, it is fundamental in digital asset preservation to ask three primary questions: preserve what, for how long, and for whom.19 Our team’s DRP covered what (all XML files, HTML/CSS files, transformation scripts, and image files of scanned documents), for how long (various durations depending on the type of backup and the current file size of existing backups), and for whom (our scholarly audiences and the general public as articulated in our original NEH proposal). Additionally, the system implemented a rotating schedule of both full and incremental backups, outlined below in Table 1. Multiple versions of full and incremental backups ensure recovery from most types of data failures.
¶ 69 Leave a comment on paragraph 69 0 Table 1: Full and Incremental Backup System Overview
¶ 70 Leave a comment on paragraph 70 0 Our Linux script functions primarily by using the Python program fwbackups with a variety of special flags and conditional statements. The fwbackups script then uses the tar archiving program with gzip compression to reduce the size of the files and combine them into a single file that can be moved to other hard drives in case of primary drive failure. This script has since been handed off to our college’s systems administrator, who monitors and adjusts it as necessary.
¶ 71 Leave a comment on paragraph 71 0 The current size of the full and incremental backups of the Brown archive is 112 GB for each backup set. The full backup is run automatically every Sunday and incremental backups run every evening. Total required backup space will soon reach half a terabyte, which may require us to reevaluate our procedure in order to keep data size manageable. Fortunately, hard drive costs have continued to trend downward and we are archiving mostly textual content rather than more size-intensive formats such as full-motion video.
¶ 72 Leave a comment on paragraph 72 0 Conclusion
¶ 73 Leave a comment on paragraph 73 0 In a recent Inside Higher Ed blog post entitled “The Incredible Privilege of ‘Building,’” Lee Bessette raises the issue of “using versus building” in digital humanities work, asking “who” does it, and “why.” It is a topic—how “building and making” serves as a heuristic or means of discovering knowledge—that Jerome McGann, Stephan Ramsay, Lev Manovich, Mathew K. Gold, David Berry, and others have also engaged in their work.20
¶ 74 Leave a comment on paragraph 74 0 We see from the way a database is used both in a material-specific way (deconstructing and representing fine divisions and relations in the text) and in a theoretical way (as a non-linear, decentralized, open-ended platform with multiple trajectories) that the database/archive potentially serves the digital humanist as a heuristic in the most enlightened sense of the word.
¶ 75 Leave a comment on paragraph 75 0 As Rieder and Rohle note, “The use of computers as instruments, that is as heuristic tools that are part of a methodological chain, may not be the most visible part of the ‘digital revolution,’ but its institutional and epistemological repercussions for scholarship are already shaping up to be quite significant.”21
¶ 76 Leave a comment on paragraph 76 0 This is the case with “building” the Brown archive relative to “respect des fonds” and the affordances of new media. It is an ongoing, dialectical process in regard to what to include in the archive relative to print publication and when to “publish” or make publically available; why we chose to represent texts the way we do; and how deep we have decided to code the texts at this time with current NEH funding. As much as it is a “product,” it is also a “work in progress.” In this respect, the long-term benefits of building this archive are three-fold:
¶ 78 Leave a comment on paragraph 78 0 One distinguishing feature setting our project apart from other digital preservation and access projects is our effort to work collaboratively with commercial industry leaders in digital document collections and databases such as ProQuest and Readex Corporation. Our dialogue with commercial entities that are also developing innovative XML content tools demonstrates how collaboration across academic and commercial borders helps spark innovative thinking about usability and sustainability issues, and allows this project a unique vantage point from which to think about digital representation and access for students, teachers, scholars, and others. Moreover, as continual upgrades transform library information retrieval systems, and as major databases such as WorldCAT and the MLA International Bibliography move toward full-text access, we anticipate that archives like ours will be well positioned to contribute to this sort of migration and open-usage environment.
¶ 79 Leave a comment on paragraph 79 0
¶ 80 Leave a comment on paragraph 80 0 Acknowledgements and Thanks
¶ 81 Leave a comment on paragraph 81 0 We would like to thank Dana Wheeles, Brandon Walsh, and Linda Garrison for contributing their expertise in writing parts of this article. In addition to Daniel Pitti, Syd Bauman, and the Advisory Board of the Charles Brockden Brown Electronic Archive and Scholarly Edition, a debt of gratitude is also owed to Alfred Weber, Fritz Fleischmann, David Seaman, Mary Chapman, Terry Frederick, Bryce Jackson, Charles Bilodeau, Jorge Ramirez, Doug Maukonen, Lee Dotson, Selma Jaskowski, Michael Powell, Darryl Tucker, Matt Dunn, John Lazar, Jacob Skinner, and others for their role in planning, building, or managing some aspect of the Brown archive since its inception in 1998 (for a complete list of contributors, see “Participants” at the project website. More recently, Jordan Rigsby, Raichele Ricklefs, and Amy E. Giroux have contributed their assistance. We extend our gratitude as well to John Schlener, David Stabb, and Lalit Arora of Aptara.
¶ 82 Leave a comment on paragraph 82 0 We also wish to thank Helen Agüera and the anonymous reviewers of the NEH Preservation and Access Program for their questions, comments, and insights concerning grant applications. The Brown archive has benefitted, especially during lean budget years, from the administrative support of Bruce Janz at the UCF Center for Humanities and Digital Research; Paul Lartonoix, Kristin Wetherbee, and Dean José Fernández of the UCF College of Arts and Humanities; and M. J. Soileau and Tom O’Neal of the UCF Office of Research and Commercialization. Lastly, we thank Fred Moody for his editorial expertise.
Mark L. Kamrath
Associate Director, Center for Humanities and Digital Research; Professor of English – University of Central Florida
General Editor, Charles Brockden Brown Electronic Archive and Scholarly Edition
Philip Barnard
Professor of English – University of Kansas
Rudy McDaniel
Assistant Dean of Research and Technology; Associate Professor of Digital Media; Director, Texts & Technology Doctoral Program – University of Central Florida
William Dorner
PhD Student in Texts & Technology – University of Central Florida
Kevin Jardaneh
PhD Student in Texts & Technology – University of Central Florida
Patricia Carlton
PhD Student in Texts & Technology – University of Central Florida
Josejuan Rodriguez
Undergraduate Student – University of Central Florida
Footnotes
License
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
Share